FrontierOR
Benchmarking LLMs' Capacity for Efficient Algorithm Design
in Large-Scale Optimization
Research Team
Minwei Kong1,*, Chonghe Jiang1,2,*, Ao Qu1,2,†, Wenbin Ouyang2, Zhaoming Zeng3, Xiaotong Guo4,‡, Zhekai Li2, Junyi Li1, Yi Fan5, Xinshou Zheng6, Xi Jing6, Yikai Zhang6, Zhiwei Liang7, Seonghoo Kim8, Runqing Yang6, Zijian Zhou12, Sirui Li9,‡, Han Zheng2, Wangyang Ying10, Ou Zheng10, Chonghuan Wang11, Jinglong Zhao6, Hanzhang Qin12, Cathy Wu2, Paul Pu Liang1,2, Jinhua Zhao1,2,§, Hai Wang1,13,§
- Singapore-MIT Alliance for Research and Technology
- Massachusetts Institute of Technology
- Northeastern University
- Uber
- Shanghai Jiao Tong University
- Boston University
- Emory University
- Northwestern University
- Microsoft
- Zhiling Research
- University of Texas at Dallas
- National University of Singapore
- Singapore Management University
Latest News
-
 [05/30/2026] FrontierOR is publicly live — 180-task benchmark on Hugging Face, evaluation harness on GitHub, leaderboards and per-task results on the website.
[05/30/2026] FrontierOR is publicly live — 180-task benchmark on Hugging Face, evaluation harness on GitHub, leaderboards and per-task results on the website. -
[05/26/2026] FrontierOR preprint released on arXiv. Final tasks, metrics, and evaluation protocol locked in.
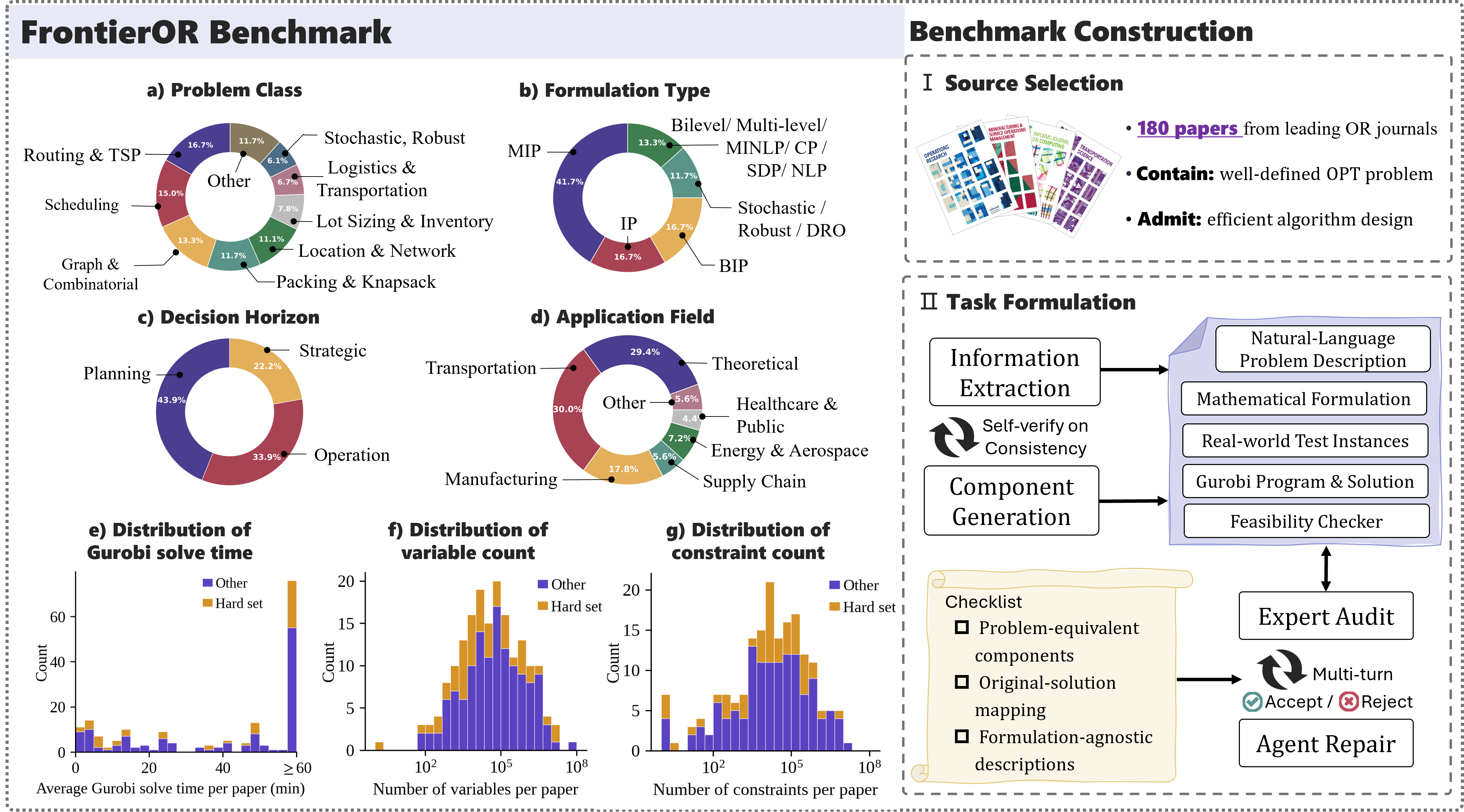
102 to 107
decision variables and constraints, with Gurobi failing to reach
optimality on
46% of large-scale
instances within a one-hour time budget. We construct the
benchmark by collecting problems from leading OR journals, and
ensure data quality through multi-round expert review.
Introduction
LLMs are increasingly used for optimization modeling and solver-code generation, yet practical operations research problems require a harder capability: designing scalable algorithms that exploit problem structure and outperform direct formulation-and-solve baselines. Existing benchmarks are limited to small or simplified examples far below real-world scale.
We introduce
FrontierOR, among the
first benchmarks to systematically evaluate LLM-based efficient
algorithm design for realistic large-scale optimization problems.
It includes
180 tasks
derived from methodologically diverse papers in top-tier OR venues,
with instances spanning up to ~10⁷ decision variables
and constraints, each task paired with a hidden, expert-verified
evaluation suite. We evaluate
seven LLMs
spanning frontier, cost-effective, and open-source models under
one-shot and test-time evolution settings.
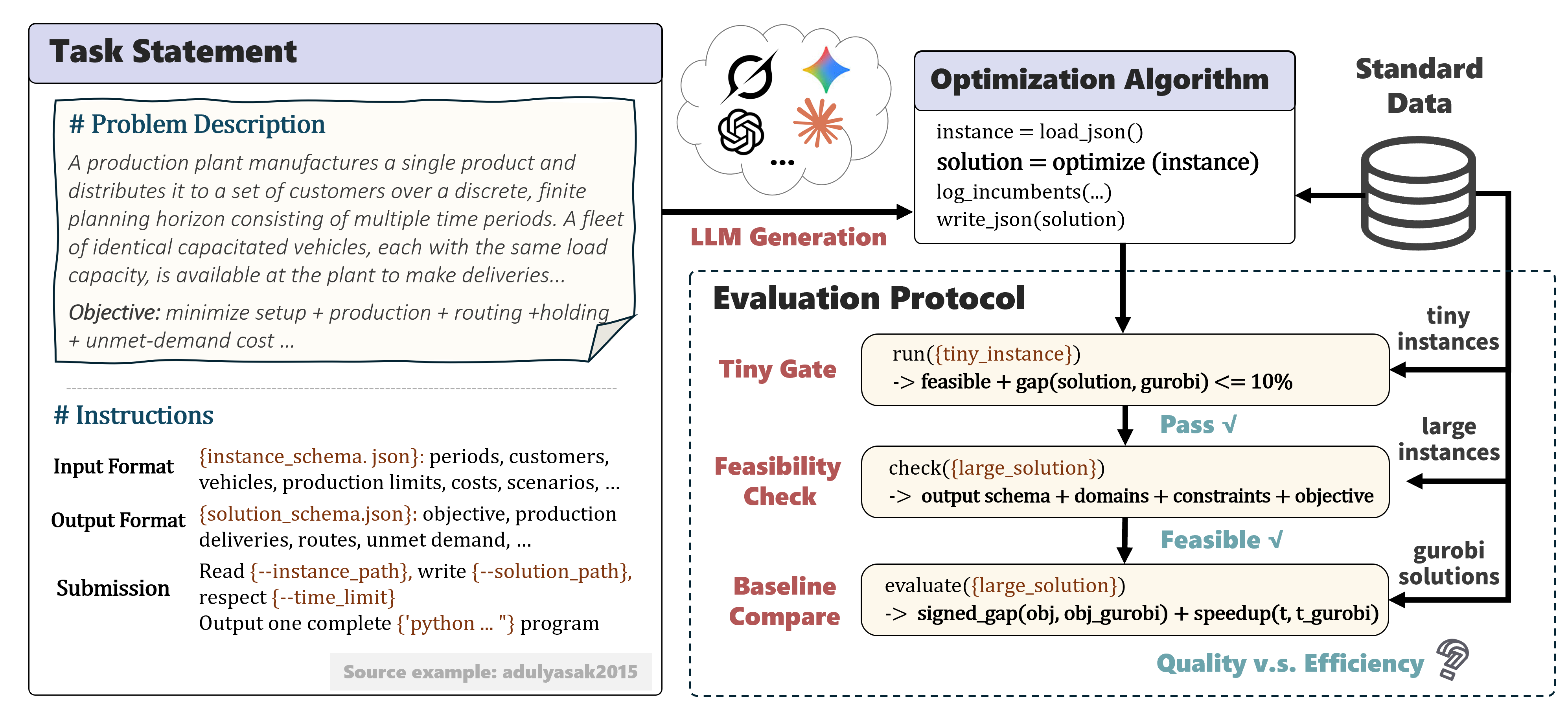
Evaluation Protocol
A FrontierOR task feeds the problem description and instructions into an LLM to generate an end-to-end optimization program. The program is first sanity-checked on a tiny instance; if it passes, it is evaluated on large instance sets for feasibility and compared with a Gurobi reference in terms of solution quality and computational efficiency.
Experiments Results
Our experiments are organized around two research questions: (1) how well do current LLMs perform under one-shot algorithm generation, and (2) to what extent can test-time self-evolution improve the generated algorithms.
One-Shot Algorithm Generation
Three patterns emerge on Full (n=180) and Hard (n=50):
-
01
Frontier models clearly outperform cost-effective ones on both Full and Hard.
On Full, frontier feasibility clusters at 0.60–0.62 vs. 0.18–0.42 for cost-effective; on Hard, the frontier band shifts to 0.49–0.64 while cost-effective falls to 0.13–0.37. The two-tier gap persists at both scales.
-
02
Execution is no longer the primary bottleneck for the strongest models.
GPT-5.3-Codex reaches exec rate 0.98 and both Gemini 3.1 Pro and Claude Opus 4.6 hit 0.93 on Full — yet feasibility and quality stay substantially lower. The real difficulty is generating algorithms that remain valid at scale, not producing runnable code.
-
03
Hard exposes sharp differences in algorithmic robustness.
On Full the three frontier models are tightly bunched (QTE 0.25–0.31); on Hard the band widens and leaders re-separate. Claude Opus 4.6 retains the highest QTE on both subsets (0.31 / 0.32), while GPT-5.3-Codex's Hard feasibility, solution quality, and QTE all fall furthest among the frontier (0.49 / 0.30 / 0.18) — its programs run, but rarely combine validity with Gurobi-level quality and speed.
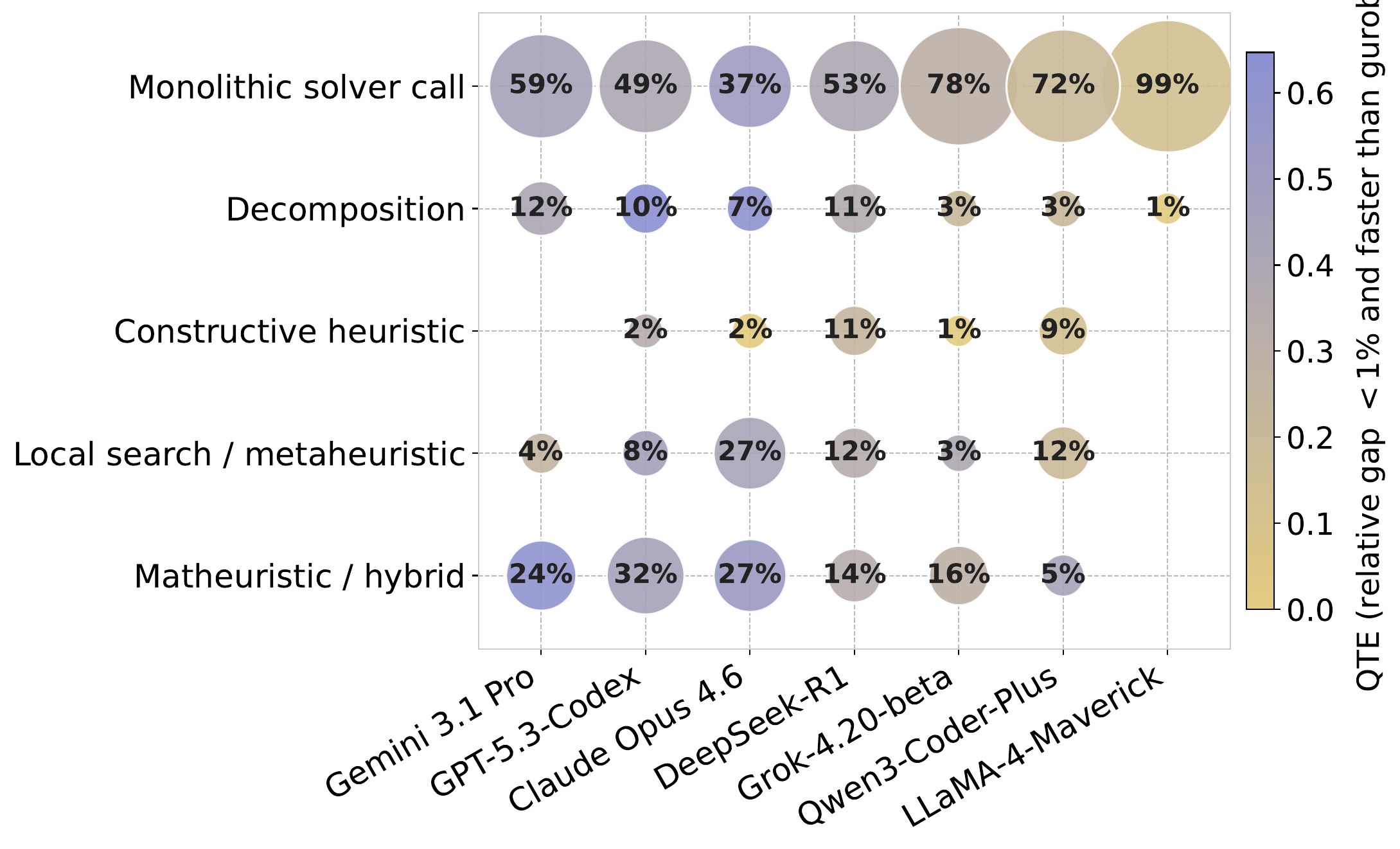
Algorithmic Patterns & Failure Modes
Looking inside the generated code reveals two complementary signals: which algorithm families each model prefers, and where each model's failures occur. Together they explain the QTE gaps observed in the leaderboard.
- Model choices differ sharply. LLaMA-4-Maverick almost always emits monolithic solver calls (99%); Claude Opus 4.6 is balanced (37% monolithic / 27% local-search / 27% matheuristic).
- Frontier ≈ non-monolithic. Gemini, Codex, and Opus more often pick decomposition, local-search, or matheuristic styles; weaker models default to direct solver calls (Qwen3 72%, LLaMA 99%).
- Hybrid & search-based methods win. At the frontier, stronger performance is consistently associated with hybrid or local-search approaches — algorithm diversity explains much of the QTE gap (Opus's balanced mix ↔ best QTE on both subsets).
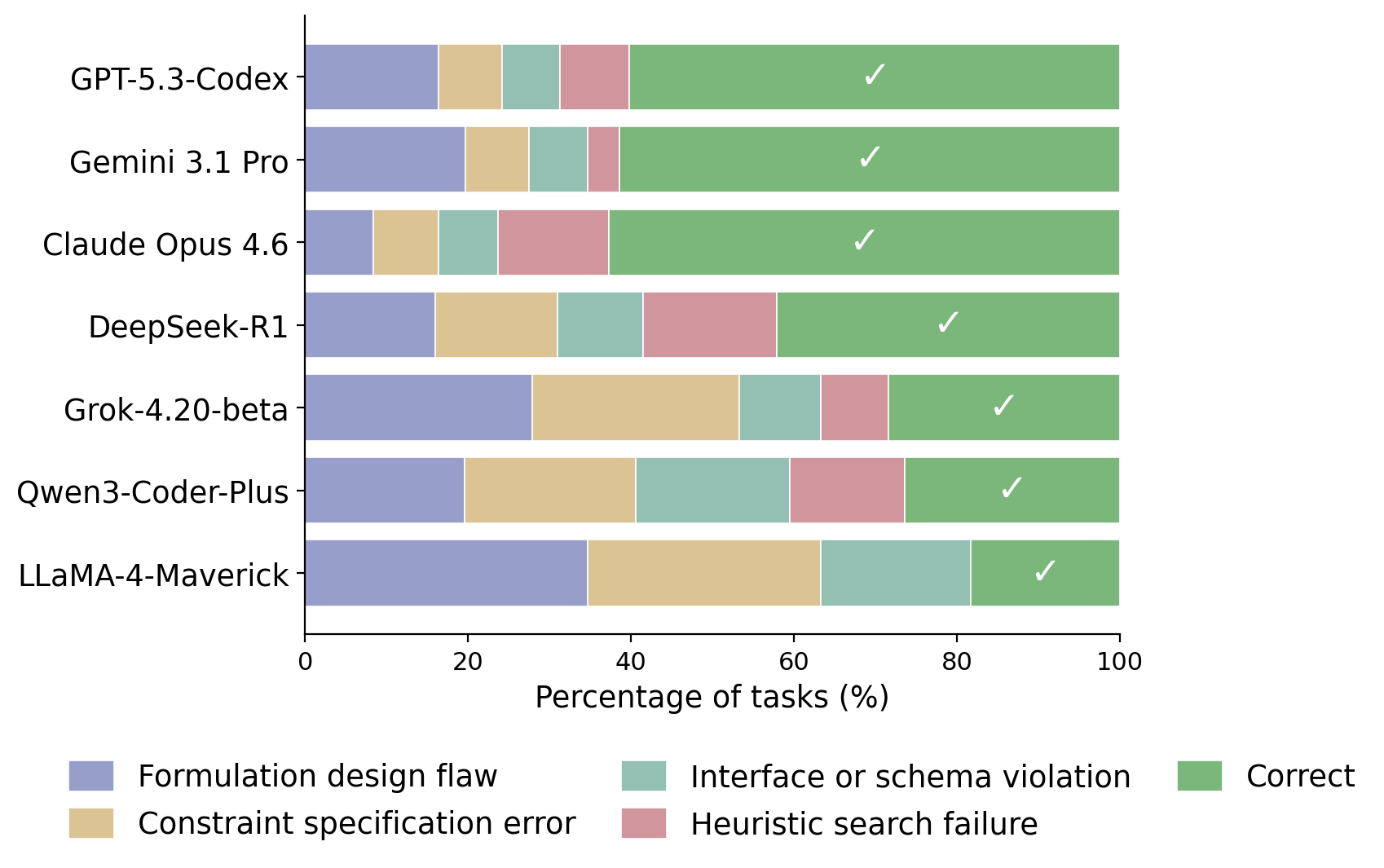
- Formulation flaws dominate. For most models, formulation-design flaw is the single largest failure category — failures happen before implementation.
- Weaker models fail earlier. Grok, Qwen, LLaMA show large shares of constraint-spec and schema-violation errors — they struggle to translate the NL task into a valid optimization algorithm.
- Stronger models shift the bottleneck. Opus is the clear exception: fewer formulation failures, more heuristic-search failures — interpretation is usually right; remaining errors come from insufficient refinement on large instances.
Performance Improvement with Self-Evolution
Direct one-shot generation, even with the strongest frontier models,
leaves many hard tasks unsolved or far below the Gurobi reference.
Self-evolving agents can iteratively refine candidate programs using
internal feedback — three frameworks
(CORAL, OpenEvolve, EoH) initialized
from the same one-shot seed, with
GPT-5.3-Codex as the shared backbone, all significantly
outperform one-shot on every metric.
Under a 30-attempt budget, CORAL attains the best solution quality and runtime efficiency, outperforming the runner-up OpenEvolve by 6% and 1% respectively. EoH shows limited improvement, suggesting that prompt-only crossover and mutation is unstable and prone to regressions on candidates that looked promising on dev sets.
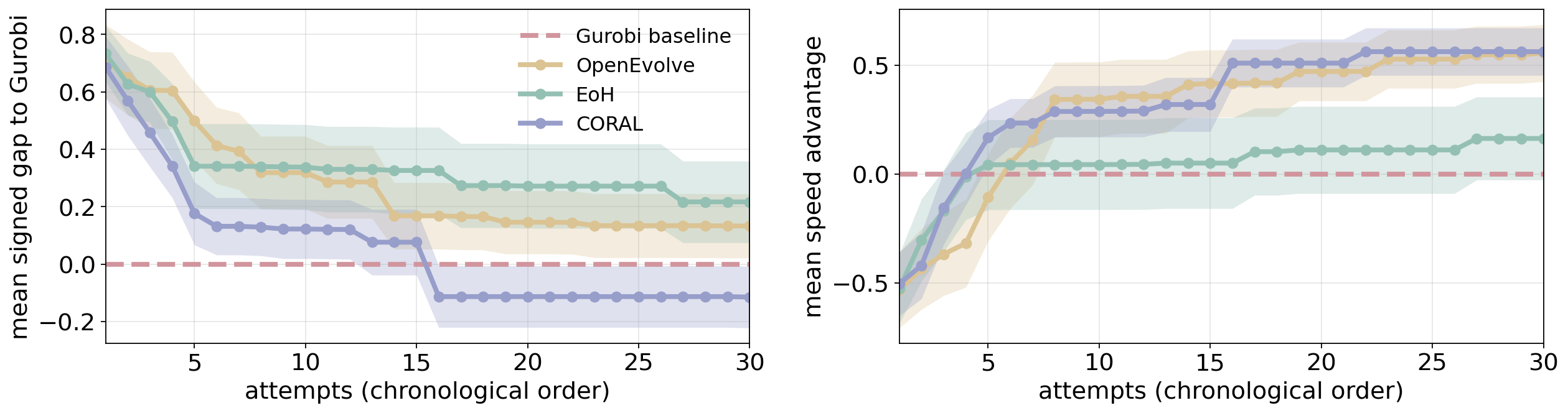
(τg − tsolve)/τg
(higher is better). Each curve averages across the selected tasks
(±1 SEM).
BibTeX
@article{kong2026frontieror,
title = {FrontierOR: Benchmarking LLMs' Capacity for Efficient Algorithm Design in Large-Scale Optimization},
author = {Kong, Minwei and Jiang, Chonghe and Qu, Ao and Ouyang, Wenbin and Zeng, Zhaoming and Guo, Xiaotong and Li, Zhekai and Li, Junyi and Fan, Yi and Zheng, Xinshou and others},
journal = {arXiv preprint arXiv:2605.25246},
year = {2026}
}